Using CPUID to get Processor Information
Chip manufacturers are constantly trying to improve the performance of their products. One way that Intel has historically accomplished this is through the inclusion of datapaths meant for certain common use cases (floating point operations in large matrices for example.) But, in order to take advantage of those datapaths, it must be supported across several layers of abstraction.
At the level of assembly language, the Instruction Set Architecture (ISA) is essentially the Application Programming Interface (API) of the CPU - it details all the functions that are available, their inputs, and outputs. However, the adding new instructions to the ISA poses issues for backward compatibility.
A program that would benefit from the new datapath would not have any way of determining if the computer supports the new instructions or not. Thus, the program would either choose to
- Ignore the performance improvements and implement the task in an older manner. Or,
- Use the new instructions and forgo compatibility with older hardware.
Fortunately, the x86 ISA (and by extension x86-64) has a solution that allows a program to use the new instructions (if applicable) without necessarily crashing on older hardware.
The CPUID Instruction
As the name suggests, the CPUID instruction allows a program to peer into the black box of the CPU and get some information about it and its features. However, using CPUID is a little different from the more common x86 instructions like add or mov. The CPUID instruction is a good example why x86(-64) is called a Complex Instruction Set Computer (CISC): CPUID doesn’t take any arguments, what it does is dependent on the content of registers when CPUID runs, and its output changes the values of multiple registers. All in a single instruction!
By using CPUID and carefully following Intel’s documentation (starting on page 3-190) on setting up the input and interpreting the instruction’s output, a program can determine if it should take one code branch that uses newer technology, or if it must use another branch designed for older technology.
Example Usage
Microsoft Visual C++ offers two simple wrapper functions for using CPUID (see below.) Some alternative ways would be to use in-line assembly (although this is dependent on compilers) or write your own function in assembly ;)
1
2
3
4
5
6
7
8
9
10
void __cpuid(
int cpuInfo[4],
int function_id
);
void __cpuidex(
int cpuInfo[4],
int function_id,
int subfunction_id
);
To summarize from Microsoft’s documentation, the values of the registers eax, ebx, ecx, and edx and returned in the cpuInfo array. The primary input value is passed in eax as function_id. An additional input value is required to access some CPUID functionality, which is passed into ecx as subfunction_id.
By disassembling the code, (I’ve used the 32-bit version of x64dbg here) we can get an example of how the above C++ is implemented in assembly.
1
2
3
4
5
6
7
mov eax, 1
xor ecx, ecx
cpuid
mov dword ptr ds:[esi],eax
mov dword ptr ds:[esi+4],ebx
mov dword ptr ds:[esi+8],ecx
mov dword ptr ds:[esi+C],edx
As expected, the assembly moves the passes the primary input in eax, sets ecx to 0 by using xor on itself, and then uses the CPUID instruction. Lines 4-7 are storing the values of eax, ebx, ecx, and edx respectively in the output array. The value of esi a pointer to the first element of the array. Indices 1, 2, and 3 are each offset by 4 bytes from the previous array index.
For a given input, each of the four registers contains 32 bits that can be used as flags to indicate the support of a certain feature. We can mask off that bit and reference the documentation to generate a true/false list of supported features.
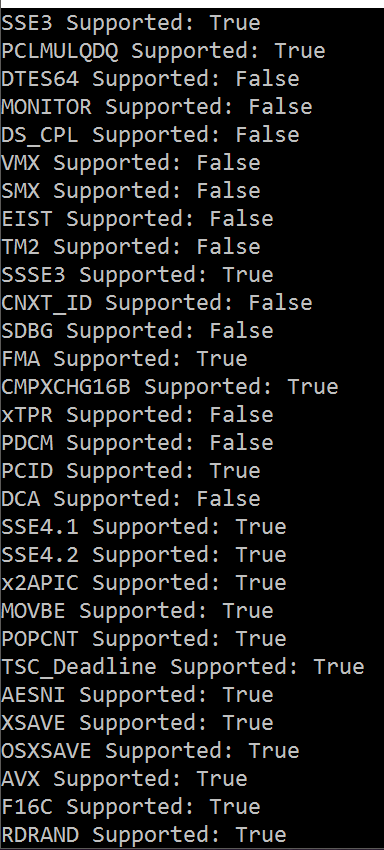
This type of information is most important at the level of the compiler, as it is the piece of software that must determine how to map code in high-level languages into an assembly language program that is as efficient as possible.